Can someone look at gg.Wolverine 2.0 (it's open source) and work out why it is getting loads of "10000 getXX methods without execute" errors against some bots (eg. mine (Recrimpo)), but not others. It seems like a serious bug in the bot. Should we remove it from the rumble, as it is just going to destabalise rankings? -- Tango
Can't fit Gouldingi's old movement in with Tityus's gun? Maybe you just don't have the hackeresque experience to do it like us! How did I fit FhqwhgadsMicro's gun into a Micro and still have it move at all? ;-) On a side note, Sedan is in 2nd currently, where it belongs (Although I wasn't complaining before I went to bed and FloodMini was in 2nd).-- Kawigi
Cooooool... Haven't touched it in 6 months yet DuelistMini is still #12 :-D --David Alves
Kawigi; Maybe you have forgot that my mini's refuse to sacrifice coding principles for codesize? =) Now that the MinibotChallenge? is dead I might let my minis grow out of their size constraints all together. -- PEZ
An interesting finding with the RH@H setup is that I think Marshmallow will find it almost impossible to enter top-10. With the ER it only fought bots in its neighbourhood which meant it could compensate for its slow learning with persistant data. But now when it fights all bots it has no room for data on all enemies... It might very well mean it keeps updating it stats on really low-ranked bots and has no room for stats on DT, Sedan, BlestPain and such bots where it should really need it. =) Expect my next bot targeting the top-10 to learn faster than good 'ol M. -- PEZ
PEZ, have you considered intelligently selecting which results to save based on score? (ie: close score means save as much data as available, solid win means save some data, blowout means save little to no data) -- Kuuran
Yes I have. But the situation is new and I think the way to go really is to make sure the bot can perform also without saved data. If Marhmallow skipped saving data everytime it got severely beaten over 35 rounds against a new bot it would seldomly save data. =) -- PEZ
Heh, obviously learning faster is better :) But what I meant is that if you win by alot then don't save data, on the idea that when you're winning by a large margin you either don't need data to trash that bot (and thus won't waste data on low-rankers) or you have enough already (in this case storing more probably wouldn't hurt you, but if it won't help too much not storing won't hurt you either). -- Kuuran
I think good guns are now a factor - in Eternal Rumble you could get a good rating by being a good mover, good guns against good movers don't make much difference to your score, good guns against bad movers makes a big difference. To get a good rateing you need to thrash a lower ranking bot by rapidly seeking out it's weak movement and hitting it. I don't think data saving is that important - DT got well clear at the top before it had fought most opponents more than once. -- Paul Evans
It seems NanoLauLectrik got the pleace it deserver :-) among the nanos, enfront of FunkyChicken, Moebius, and Kakuru. It makes me happy. -- Albert
Apoptygma bothers me. It's contents are mostly things I said 'wouldn't it be cool if I could fit this into a micro?' about, so I didn't expect it to win any awards in competition, but I still expected it to be around 40-50. I guess I'll have to make a competitive version that ditches the VirtualGun? array and has a stronger movement (call it Berzerk, maybe? ;). -- Kuuran
Good guns is certainly the major factor now. Marhsmallow's guns aren't too bad I think, once they have taken 500 rounds or so to gather data. =) I can't get my movement together now at all. (I have spent two months on it and I still get slaughtered in the movement challenge....) But when I do I'll start working with the Tityus guns and see if I can climb the targeting challenge ladder. Don't expect me to stay out of top-10 for too long. =) -- PEZ
"I don't think data saving is that important - DT got well clear at the top before it had fought most opponents more than once. " Well, I used the same robocode installation for both beta 1 and beta 2, so my copy of DT had hundreds of rounds of data saved from the first beta when the new rankings were started. :-P --David Alves
I forgot about that - I think DT can hod data on about 70 opponents - (the 70 most recently fought) - saved data for DT will be at best used in 2 in 5 of the battles once it has trained up - with more opponents even less - I wonder if it will keep it's lead after that :) -- Paul Evans
DT obviously has guns that can perform very well without saved data. That hardly is an issue for debate. =) -- PEZ
DT also takes about 500 rounds of saved data to hit. (ok, maybe a slight exaggeration, or maybe it still can't be hit at that point) -- Kawigi
I think that Kuuran hit the right answer (or at least I agree with him =^> ). I think that the move to this format will force people to do a couple of things they have never thought about before. For one I think that it will become more important to selectively save data about bots than ever before. It was the first thing that struck me about this format. I also think that people will need to start adding algorithms to trim their data directory as well. It will do me no good to recognize that I should save data on this opponent if I have no mechanism for removing data that I could do without. I am also wondering if it would be possible to figure out from my stats buffer that the movement in one bot (Cigaret for instance) is the same, or close, as the movement in another bot(Sedan for instance) and simply reuse the data from one for the other. -- jim
I've also thought before that it would be an interesting test to try using data from an old version of a bot on a new version (in a VG sort of setup), and even extending it to try saved guns from other robots of the same package on new robots. It occured to me, though, in doing some version-type stuff, that if the new movement is different, it could prevent my gun from becoming really great against that opponent (with non-rolling stats), but it would still do better in the beginning because of KentuckyWindage. -- Kawigi
PEZ and Albert, I like the the new Rankings Page! I think this is very good stuff. Thanks! jim
I guess the page that is new is the detailed ratings page. I like it too! But I have nothing to do with it. It's Albert's work with some good suggestions from Paul. About sorting. If someone knows a good cross-browser way of sorting HTML tables we could add the sorting on the client side. In line with the whole @Home thought. =) -- PEZ
I can write a script to do sorting on the client side if you like (I do Javascript + CSS for a living :-P) Only problem is that it won't work in older browsers, only recent versions of Mozilla, IE, Opera, and other browsers that support the w3c DOM. In particular, Netscape 4 is hopeless. --David Alves
Netscape 4 has been hopeless for very, very long. It only need to work in modern browsers. If you can make it so that it works in my browser (Safari, Konqueror based MaxOSX? browser) it's a bonus. I've only found a few solutions out there that works here. Most work on IE5+, some work on IE5+ and Mozilla, very few on a broader range of modern browsers. The problem with the solutions I have found Googling around is that they are either huge or commersial or both. What do you say Albert? Would a client side sort be desireable? -- PEZ
I figured out how to do a quicksort in scheme... (Just thought I'd add that as an irrelevant comment) Since we're technically chatting abount rankings here, though, I'm noticing a sort of division here. There are bots which do extremely well against really bad bots and bots which beat the good bots well, but don't beat the less competitive bots by as much as they should (I tend to think the former are primarily pattern-matchers and the latter are primarily statistical variants, or even robots with bad guns and good movement). Whatever the reason for this, it appears that some robots do better when only faced with bots of their own caliber, and others do better against just everyone. My question is which is better? Is it better to include SandboxDT vs. SpareParts in the final ranking, or to focus on how SandboxDT does against Wilson, Iiley and I (and PEZ or whoever else pokes their heads in the top 6). I'm curious what the opinions are, because at the moment, I'm running tests for the RobocodeLittleLeague using completely random pairings, but I suspect there are some advantages for stability battling bots against those close to them. -- Kawigi
Both variants have their merits. But I strongly believe that a really good bot should trash bots at the bottom of the rankings and play well against top ranked bots. That's one of the things I really like about the RH@H and I think that why it hasn't been done before is mostly because of the lack of computing power. The robrumble rankings tell a truer story than any league preceding it I would say. -- PEZ
I keep thinking the best rankig system is one similar to a football league (ie. all play against all, and get points by winning). In this context, I like the idea of random pairings (because at the end everyone will play against everyone) but I don't like using the scores to determine wich bot is better (Can you imagine a football league where the winnner is the team that scores more goals during the league, regardless of it it wins or loses the matches?). For me the best ranking would be one with random pairings, but that doesn't uses the score but the battles win/lose ratio. -- Albert
About sorting: everything that we can do in the client, we should do in the client. So I agree with that script (even if I can't imagine how it works). -- Albert
About scores versus wins/losses. There are different goals with RR@H and a soccer league. The former aims to show how the bot ranks against eachother and the latter how the teams fair in the league. With this I mean sport leagues have much more room for randomness and injuries and day-to-day circumstances and such. A bot is a bot and unless we have enough computing power scores is the way to answer the question asked. But, is it correct to calculate the number of wins/losses from the "% score" and number of battles fought? If so I could maybe also publish that sort of league too. -- PEZ
I know you do't want to add load to the server, but the simple way to provide a sort is with an optional "sort=" option on the RankingDetails? page (used by links on the headers of the details table) the sevlet can sort the table data in a jiffy. -- Paul Evans (I can have a stab of writing it if you wish).
Yes, I don't think it will add too much load to the server (we are a rather small community after all). The reasons I suggested client side was to honour the @Home philosophy and so that Albert wouldn't have to do it in the servlet side (since we obvioulsy have more pressing matters to fix there). But awaiting David's client side solution please feel free to add that sort to the servlet. I have a CVS server here if you and Albert (and whoever else starts hacking at the same files) would want that help to synch your changes. -- PEZ
I can't look at it today, I have a golf match, if it looks like no one else is looking at it come Sunday/Monday? I will have a go - but anyone else is free to do the job as I have no servlet experience and the only packages I have ever written start with pe. -- Paul Evans
You don't need any servlet experience to sort some lists. I've seen in the source code you have published that you know how to use the API. =) -- PEZ
How are the pairings chosen on the client side? Could it actually be a psuedo random pairing as opposed to a truly random pairing? I ask becuse [Jekyl] has only faced 130 of 185 possible participants through 255 battles. There are 50+ bots that it has never fought before. I am sure that others are in the same situation. How much could this affect a bots overall rating, if at all (especially given that a bot may compare well to some of the top 25 which it has yet to face and poorly vs some of the bottom bots that is may have faced mulitple times)? Is there any way to tell a client to look for matches that have not been fought? Is this outside the design goals of RoboRumble? -- jim
Why would the pairings be pseudo random. Doesn't it sound quite likely that you after 255 battles have not been paired against some 50+ bots out of 180? And, it shouldn't affect your ranking I think. Other have fought those 50 bots and you have fought those others. -- PEZ
Heh, on the subject of facing the entire spectrum, overall performance is what is measured here. Look at Apoptygma, it scored near even against (or even beat) many bots 50+ or even more positions above it, but lost by blowouts to bots ranked around 1100. Comparing well to some better bots might find it ranked around 50 instead of around 100, but in fact it's far too unreliable to be ranked higher than it is once you consider the whole picture (as I've come to realize). In that sense this is a great system. On the subject of sorting, I was going to say something along the lines of what Paul said, there are plenty of blazing fast sorts for numbers. I have no servlet experience either, but I could write the sort class itself. -- Kuuran
Thanks Kuuran, thats mostly what I was interested in knowing. -- jim
What would you think about outputting the data as a javascript array? The trouble I'm having isn't building a sorted table, it's trying to get the data from the original table into an array. Something like:
var results = new Array(); results = [ ['header1', 'header2', 'header3'], ['data1', 'data2', 'data3' ], etc...
Not a problem, if you tell which syntax I should use. -- Albert
Use this syntax:
var results = new Array(); results = [ ['header1', 'header2', 'header3'], ['data1', 'data2', 'data3' ], ['data1', 'data2', 'data3' ], ['data1', 'data2', 'data3' ]]; Give me a div with an id of "resultsTable" like so: <div id="resultsTable"> <table> ... </table> </div>--David Alves
Heh, someone's been running only nanos, which is good for their stability, however, until micros and minis get as many matches (and can move further from 1600) those divisions are hilarious. Not that I mind having a top 3 bot in every mini weight, but somehow I don't think NanoLauLectrik, Smog, NanoSatan and FunkyChicken quite as legitimately occupy top 4 in micros and minis as they do in nanos ;) -- Kuuran
How do I run only Nanos/Micros?/Minis?? --David Alves
Nevermind, I did it the brute-force way by changing particip1v1.txt to only contain bots with codesize < 1500. --David Alves
Why can't you just wait a few days? Doesn't the nano-only-run show that it destabilizes the rankings for the other games? What do you think mini-only does? Yes, it can't do it very much since the roborumble game has quite a few battles in it. But still, this is completely unecessary. It only complicates the system if we have to introduce filters against all sorts of scenarios. Run the client as-is is my suggestion. In due time we will have the rankings. If your more curious than that install Tomcat and the servlets locally. As it stands I'm considering we should wipe the current rankings files so we clean out these experiments. Someone please tell me that's not necessary? -- PEZ
It was me. I was trying the new client functionality, that allows you to select the category to run. Today I'w run minis :-) And there is a reason there... the number of nano matches represents a % equal to (NANOS/TOTAL)^2, being NANOS and TOTAL the number of NanoBots and bots. If they don't get some help, this league will starve. -- Albert
Umm, I don't quite follow. But I'm sure you know what your are doing. =) Maybe you should post some rules on how the client should be used against this server. (If peple start other servers they can pick and choose rules of their own I mean). Distributed computing is powerful, but if more than one person starts manipulating the results (here "manipulate" is not necessarily negative) we will start getting problems. One way to somewhat enforce rules is to place the settings on the server as we have discussed before. (That means all settings except server URL and name I think). Maybe with that scheme of "if no server available when I start, use previous settings and sort the settings out when I upload" to not impale the rubustness of the system we have today. -- PEZ
I think PEZ has an important point in the paragraph 3 spots above this one (Just got my first edit conflict :-P). I wanted to get more accurate minibot ratings soon, and it sounds like Albert wanted to get more accurate nanobot rankings, but there is a potential for mini/micro/nano-only clients to destabilize the overall rankings. Imagine the following scenerio: a nanobot, SuperNano?, easily beats all other nanobots, but, like most nanobots, doesn't do very well against large bots. If someone is running a nano-only client, then SuperNano? will have a higher % of matches against other nanos than it should being used to calculate its rating. I'm talking about its overall rating here, not its nanobot rating. Since matches against nanos are wins, it will have a higher rating than it should. A good workaround might be to have mini/micro/nano-only clients inform the server that they are nanobot-only, then have the server use those matches only in the calculation of ratings in the nano league, don't incorporate them into the general league. Or just don't run mini/micro/nano-only clients. :-p --David Alves
Nanos represent aprox. 30/200 bots in the competition. It means that only 30^2 on 200^2 are battles between two nanos that can count for the competition (it is aprox. 1 battle for each 40 battles). Of course there are less nanos, so you don't need the same number of battles as in the general competition. But in any case, the nanos competition moves 6 times slower than the normal one (ie. it took 2 days for the general competition to settle, it would take 12 for nanos to do it). So I though we need a system to speed up these leagues, and that's what i'm testing. About rules to run the clients: With the current system, and once the ratings are stabilized (now micros and minis are not), there should't be any problem in running more battles here or there (well, I can think of some obscure tricks to benefit a bot, but I won't post them here for now :-)). About server sending information, I have been thinking about that also, and may be is a good solution, as long as it is compatible with the current system. -- Albert
We wrote at the same time :-) I like the idea. I'w change the client so if you decide to focus in a catagory, results are only uploaded to that (and lower size) competitions. -- Albert
I think Paul's idea with setting percentages in the client for the various games should be considered. While we have a known set of games these percentages could be hardcoded into the client. I don't follow the math up there but it seems like you could keep the same pace in all games by setting these percentages right. (Provided you also implement David's scheme of course). -- PEZ
A client in megabot mode send in results as follows:
(10 * 9) / (100 * 99) = 0.9091 % nanobot matches (30 * 29) / (100 * 99) - .009091 = 7.8788 % microbot matches (60 * 59) / (100 * 99) - .078788 - .009091 = 26.970 % minibot matches 1 - (60 * 59) / (100 * 99) = 64.242 % megabot matchesA client in minibot mode will send in:
(10 * 9) / (60 * 59) = 2.5423 % nanobot matches (30 * 29) / (60 * 59) - .025423 = 22.034 % microbot matches 1 - (30 * 29) / (60 * 59) = 75.424 % minibot matchesA client in microbot mode will send in:
(10 * 9) / (30 * 29) = 10.3448 % nanobot matches 1 - (10 * 9) / (30 * 29) = 89.6552 % microbot matchesA client in nanobot mode will send in 100% nanobot matches
From there you can calculate what % of the time the client should be in each mode to balance out the 4 types as follows:
.25 / .6424 = 38.9166 % of matches should be in megabot mode
(.25 - .10496) / .75424 = 19.2299 % of matches should be in minibot mode
(.25 - .07303) / .89655 = 19.7387 % of matches should be in microbot mode
22.1148 % of matches should be in nanobot mode
I may be off by a little due to rounding but I think that the math is correct. Now all you need to do is apply the same method to the real numbers for mega/mini/micro/nano. :-P
It looks like NanoSatan2 is doing just a /bit/ better!!!! :) -- Kuuran
Why are results only posted weekly now? I mean, sure, every half hour was excessive, but what about once per day? --David Alves
There is no need to wait to see the results. You can see then on real time. The weekly ones are to have some "stable" rankings. Go to RoboRumble/CurrentRankings to find the link to the real time rankings. -- Albert
The best part about the dynamic one is they show who the real best nanobot is. -- Kawigi
Scary. I just got an impulse to write a nano. But I managed to fight the impulse back. =) -- PEZ
How come marshmellow hasn't had any battles in over 30 years? 1970 looks like a default start date...
21 pez.Marshmallow 1.9 1748.87 1154 1-1-1970:1:0
The details page says the latest battle was a few minutes ago. (i just uploaded a few hundred, so chances are marshmellow was in at least on of them) That seems correct, so why isn't the info coming from the same place? -- Tango
The Rankings info comes from a summary file. A file that always is updated when new results are uploaded. This makes it extra vulnerable for the concurrent updates we still have. While that is so Rankings info will always be a bit strange. The details pages are not at all as likely to be updated cincurrently though so that info will mostly be correct. However, the concurrent update problem will be fixed eventually. It's just that I haven't found the time when I feel alert enough to do it. If someone else feels like doing it the DataManager class is where to do it. So it won't conflict with updates to the functionality of the servlets. There's some outline code in there that is commented out which you might or might not want to follow. Whoever accepts this task (including myself), please state so on the todo page. -- PEZ
The ratings file is damaged and only 70 bots appear in it!!! Could it be another concurrency issue? -- Albert
It probably is. I'll give it a quick check and see if I can fix the temporary problem. And on Saturday I'll try to find enough time to fix the cuncurrent update problem. If I can't fix the 70-bots problem quickly, it'll have to wait until at least late tonight (CET). I'm going to a late night fotball game (AIK vs Valencia, UEFA Cup). -- PEZ
The file appears to be truncated. But it grows quite quickly again. Now it's 102 bots in the file. And it seems that the bots that were temporarily away come back with their rating intact. I'll leave it be for now. The upload clients will rebuild the rankings by themselves I think. And on Sat I'll see if I can write that update queue handler. -- PEZ
Just one more observation. It seems this was a good way to get rid of those old versions of the bots that lingered around. =) -- PEZ
In fact, there should be only small fluctuations, as the basic data is in the details files, and bots are added to the rating files when they fight a battle. No need to fix it (it will correct itself). Just that would be good to avoid it happen. -- Albert
There must be something wrong with the way the ranking is calculated, how do you explain vuen.cake's situation? It started by beating that trinity guy with a score that would, if I understood it right, place it around 20th-30th, yet it went straight to the 2nd place. Since then it got 3 more below average results, but didn't move down a single spot... even with a small number of battles the ranking system should already know where to place it... -- ABC
I had a small panic when I looked at the active rating table - but it seams I do not have to worry too much. Cake looks like it started with ranking far too high - possibly DT's ranking - was there a previous version, if not it should have started at a rating of 1600. -- Paul Evans
Yep, that's probably what happened. But still, It should have gone down mutch faster, imho. Everything seems to happen a bit to slow with this ranking, wouldn't that "multi-pass" sugestion of yours make it a bit more responsive? Or maybe make a bot fighting with it's current neighbouring adversaries a little more probable? I like the fact that everybody fights everybody else, unlike the ER, but the cost seems to be a very slowly stabilising table... -- ABC
Maybe it will be able to stabilize faster when more people start running the software; I've basically been running it for 10 hours a day since I have it, because I can leave my computer on all day while I'm away or in class. Still, there has to be a bug in the ratings somewhere to explain Cake's situation; it's nowhere NEAR that good, and shouldn't even be in the top 100 (probably not even the top 150). I thought bots were supposed to start really low on the list and move up as they fight, rather than the other way around. If the average index is rolled, is the rolling initialized with the first value given? The rolling average should start initialized at zero, and have to roll its way up; initializing it with a non-zero value will make the first battle fought take like 50 other battles to wear off. I'm just guessing anyway, maybe the bug is something completely unrelated. meh. -- Vuen
The problem is not the speed at witch battles are run, after over 133000(!) battles fought most bots are still going up/down too often. -- ABC
Wow, Cake currenly holds a momentum of -1192.5 in 36th place. Heh. Looks like its ranking was short-lived :) -- Vuen
The problem with Cake's initial rating is probably related to the /ConcurrentUpdateProblem. And the issue with how slow a bot finds its rating neighbourhood will be fixed soon when the new client arrives that prioritizes battles where new or updated bots are involved. With that client in place it will only be a matter of hours at the current battle speed of the rumble. However I also think that at some places in the ranking tables the bots change places a bit too often. I suggested somewhere on this wiki that we maybe should consider lowering the impact the result of a battle has on an older bot when it meets a new/updated bot. Currently new bots start with a ranking of 1600 (well, all except Cake) and updated bots start with the ranking of the previous version. Say this initial ranking is way off. Say it's way too low (like if it was Paul Evans' new MegaBot) for the sake of argument. Then bots fighting this bot will have their rating adjusted wrongly, won't they? The system should favour age before beauty or something like that I think. -- PEZ
I thought it already worked like that. I thought the first 20 battles of any bot only effect it's ranking, not it's oponent. Was that changed at some point? -- Tango
I wasn't aware about that. -- PEZ
About that panic, Paul. Do you feel it creep on to you now when BlestPain is only 2.6 points behind DT?
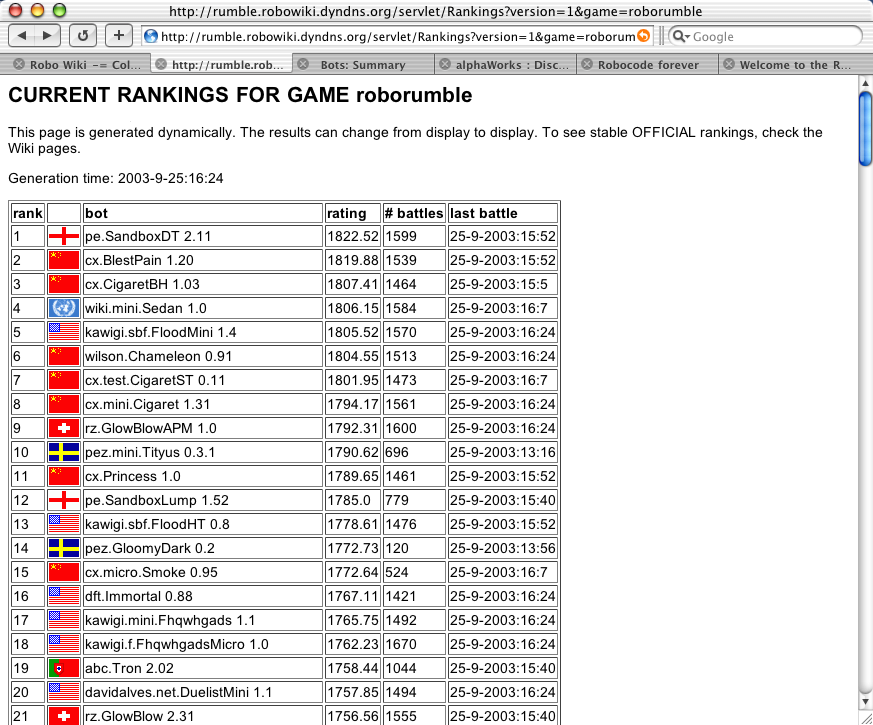
-- PEZ
I wouldn't worry too much, that small difference must also be a consequence of the strange way this ranking is being calculated. There is no way BlestPain could be considered "almost as good as" DT, imho. There are many bots out there that can defeat BP, even if by a small margin, but I don't know of a single one that comes close to winning against DT. And, in this case, both have fought over 1000 battles, it is not a case of lack of results, there must be something wrong with the expected score formula or with the way the rankings are being recalculated. -- ABC
Its true that in 1000 maches its hard to beat DT. But don't forget that rumble acts like no saved data. The bot should learn as soon as possible in 35 rounds.(More oportunites against DT) Saving data doses not help to much beacause the battles run on diffrent clients. This is the new constraint of rumble. --SSO
The first 20 battles affect the enemy ranking (I removed the restriction when I changed the way ratings are calculated and never added it back - I'w do for the next release). -- Albert
It's true you have a small chance against DT if your battle is the first one on that particular client and you are lucky enough to win those 35 rounds, but that also affects everybody else, including BlestPain. Even with 35 round battles there is currently no bot that comes close to DT's performance, and this ranking doesn't seem to reflect that, imo. -- ABC
Note that currently, DT has been beated by Tron, Smoke, Teancum, SandboxLump and Chamaleon, and ties to Sonda (6 bots). BlestPain has been beaten by Tron, CigaretBH, Cigaret, SandboxDT and Sedan, and ties to Smoke (6 bots). So it is not performing much better than BlestPain (just because it is able to beat bots by a wider margin). The conclusion to me is that the ranking system is OK. Note that ER was specially favourable to DT, with short 10 rounds matches, where movement and saved data were the key. Now with longer games and many clients running battles, guns and fast learning play a bigger role, because (1) you play against much more enemies, so you play less rounds against a given enemy (2) battles are executed in different clients. -- Albert
Your right of course, I didn't check BlestPain's (impressive!) record, and was basing my thoughts on the fact that Tron's current development version can beat BP by 60-40 and get's crushed by DT 30-70 in survival, it just barely wins in total score against BP and looses 60-40 against DT... I assumed that the general trend against other bots would be something similar, I forgot that Tron has a somewhat "different" way of dodging. ;) -- ABC
Btw, BlestPain just took 1st place away from DT, I still find it a little suspicious... ;) -- ABC
Heheh, I was just coming to mention that ;) and GARB, already almost 200 battles and Fractal still hasn't faced SandboxDT... -- Vuen
SandboxDT is now in 4th place and going down! :O -- ABC
5th now. Something's obviously wrong. I suppose it's kindof redundant of me to post this, but, meh. It's 11 am, and I have 30 pages to read (<-and understand!) and 5 online physics assignments to do before I go to bed. In other words, I'm wasting time here =) -- Vuen
It's not necessarily the rating system that flukes here. It could be DT itself that has some bug (someone mentioned an array index out of bounds). Now the count of bots that DT loses to are 8. And it ties against a few more. Interestingly all this stir is happening above my bots. Tityus and Gloomy's rankings are rock solid. Until they meet DT maybe. =) -- PEZ
I'w take a closer look, but I agree with PEZ that probably the problem is not in the rankings (may be DT is has some bug in some new client?). All my bots are quite stable now, and its ranking is solid and logical. -- Albert
I am beginning to suspect the /CuncurrentUpdateProblem? again. Think about the Cake incident. It looked like Cake got initialized with DTs rating, right? Possibly something is wrong with DTs record. -- PEZ
I have been analyzing the individual battle records, and there are some strange ones for DT. My theory is that there are some clients that are running DT in challenge mode: @people running the clients: please check DT is running in normal mode (not challenge one). @people with bots that can run in challenge mode (like DT and Tron): Please consider releasing a version that runs only in battle mode.
-- Albert
That's it! And It's probably my fault too. I have been leaving my work computer on all night running battles and I have RR@H installed in the same folder I use for testing... That explains Tron's inconsistence too. :-\
Just checked it, I was running DT in reference mode. Is there maybe a way of deleting all the battles run by me since yesterday? -- ABC
Not an easy one, but as long as the problem is solved, the ratings should fix themselves fast enough. -- Albert
Eek. Perhaps we should warn people who install the client to install in in a seperate folder... -- Vuen
We will do. In any case, I insist on releasing "safe" versions that do NOT run in challenge/reference mode (and when possible compatible with java 1.3). -- Albert
It should be made a requirement rather than a suggestion that rr@h should be installed in a new blank folder. So many robots now come with configuration changes now that affect their performance that not only is it impossible to remember which ones you've set properties on, but it's a complete hassle starting up rr@h because you have to reset everything. While this is the user's fault it still degrades the credibility of the 'ease of use' of the rr@h software. Plus, bots that have been downloaded before others or that are used to test more than others gather much more data. Suppose you've been watching SandboxDT fight against all sorts of opponents to watch its movement, then download Tron and run the rr@h client. SandboxDT will have information on everyone while Tron will be blank, giving SandboxDT a huge advantage in the rumble. This should not be allowed; a fresh installation will keep everything seperate from your test robocode. When I first installed rr@h I created a folder called rrhome, installed robocode in it in c:\rrhome\robocode, then unzipped the rr@h software into c:\rrhome. This way anything I do in robocode has no effect on my rumble client. I'll check the license agreement for RC, and if we can package it with it I'll make an easy-install zip file containing robocode that automatically unzips to c:\rrhome\robocode. -- Vuen
Yup. That's the way to go. If you do it with something like rrsetup.jar you can make it copy any existing robocode installation. That way you don't need to worry about any license stuff I think. -- PEZ
Any initiative that helps reducing uncertainity about rankings is great. So please go ahead with it. Please, remember to package codesize.jar also, since the client needs it to evaluate bots codesize.
On the other hand, I keep thinking that the ultimate reponsability for this kind of errors is for the developer of the bot, not the one running the client. People must be concious that the new environment is not thigthly controled as it was on the ER or MinibotChallenge?. If someone feels his bot needs data, then he is responsible to package it into the .jar file it delivers. It also applies for parameters (if someone wants to make sure it doesn't happens again, then just remove them from the bot). And of course, we will do whatever posssible to avoid it to happen. -- Albert
Since I am a bit unsure whether "top 6" was a completely arbitrary set. Would you choose that set today to? =) -- PEZ
It seems DT is recovering slowly. Albert is there anything I can do with the datafiles manually to reset DT back to where it belongs? It is unfair that the snapshot archives from Sept 2003 (which is settled tomorrow morning, CET) should list DT anywhere else than at ranking #1. Even considering RR@H is still in the testing phase. -- PEZ
I'w try to run DT focused on the bots with "wrong" results. It should correct its %score and speed up DT recovery.
It's fixed now. Again: @people running the clients: please make sure you don't have bots in reference mode. @people with bots that can run in reference mode: seriously consider releasing a "battle mode only" version for the RR@H. -- Albert
Or rather, release "reference mode only" versions and keep the vanilla version in "battle mode". -- PEZ
Hmm... I still think that it's unfair to those who provide these tools that they would have to release multiple versions. It's a real pain to have to package and upload two versions of your bot, and it will clutter the repository with duplicates of every bot. For example, right now Fractal has a properties file that allows it to graph its opponent's movement curve directly onto the battlefield as it fights. This makes Fractal far more vulnerable to the above problems than even the reference bots; the RR@H client will run robocode.jar rather than RobocodeGLV014, so if Fractal is left in GL mode, even if the RobocodeGLV014 installation is there Fractal throws an AccessControlException? for trying to access them and effectively gets a score of 0. If it's not made a requirement to have RR@H installed in a seperate folder, in the next version of Fractal I will simply remove this graphing ability altogether and not bother releasing a GL version; and I think other bot developers may do the same. -- Vuen
Of course it should be made a requirement. But it's not easily enforced. The packaging you suggest will help and from there there shouldn't be too much of a problem any more. But still, if you want to be sure; Make sure your battle bot only does battle. -- PEZ
On the contrary, it can be easily enforced; you can make the RoboRumble client for example delete any of the .properties files that Robocode creates, such as window.properties, after Robocode creates it. Then when RR@H is started up again, it can check if window.properties exists before starting up Robocode. If it does exist, that means the Robocode installation was ran seperate from the RR@H client, and the client should perform some appropriate action. It could perhaps simply warn the user that it is being run an unisolated installation, or it could refuse starting up, or what it could do is delete the folder in .robotcache for every bot in the rumble and refresh the bot list. The first and last are what I would consider appropriate action; warn the user with a swing messagebox, and refresh all rumble bots back to their original .jar contents. -- Vuen
Robocode refreshes it for you if you just "touch" all bot jars. But I think this would be too tough. For non-rr@h-purposes people might want their robotcache left as it is. Appropriate action would rather be to just quit. In any case you still risk that your bot is running in a non-battle mode. The best way to prevent that is to release a bot that concentrates on battle only. -- PEZ
Don't worry about Fractal. RR@H server refuses any result with an score of 0, because it assumes the bot crashed and the battle is not valid. The same will happen for example, for a bot not compatible with java 1.3 when someone runs RR@H under java 1.3. The real problem is for bots that will run normally but can behave diferently depending on the set-up. -- Albert
Ah. Well that's good to know :). Thanks Albert. On a side note, VertiLeach 0.2 is in 3rd place! -- Vuen
Now it has dropped to 6th. Its performance is a bit too arbritrary for a top-3 bot maybe. On the other hand, it's designed to kick MiniBot ass, and it does. Let's see if it can cling on to that #1 spot. I'm incredibly proud of it winning the RobocodeLittleLeague 1v1 mini division too. =) Now, I might let it grow into a megabot which can maybe perform a bit stabler. -- PEZ
It's not fun to see the development of the minibot rankings! Fight Verti, fight! -- PEZ
Can someone see a reason or why GlowBlowAPM suddenly wakes up and goes up on #1 in the minibot rankings? Looking at its details it seems to lose against more bots than FloodMini and certainly more bots than VertiLeach. I know GlowBlowAPM is a strong mini, just that it's surprising to me that this change in ranking happens after 700+ battles. -- PEZ
I don't see this as all-of-a-sudden at all. GlowBlowAPM has been #1 minibot before, and it's battled back and forth with FloodMini for it ever since the minirumble started. It isn't really made to beat FloodMini and VertiLeach, it was meant to trash robots who used pattern-matching and head-on aim. Note that HumblePieLite is one of its significant problem bots, too. Not only is GlowBlowAPM's movement optimized against itself, it dodges itself. I agree, though, that it may be more significant that FloodMini and Sedan only has a losing score to something like 5 robots, and VertiLeach still only has a losing score to FhqwhgadsMicro. -- Kawigi
Well, I think the variation with +/- 30 points in gap between these two bots feels a bit on the unstable side. Don't expect to see VertiLeach lose against more bots. In my tests it wins clearly against all minis. Which made me assume it would rank #1, but there's obviously something about the ranking that I don't understand. I'm currently uploading version 0.2.1 of VertiLeach which according to my tests (which are now based on RR@H) is marginally better than v0.2 against minis and clearly worse than v0.2 against all-size bots. This is a bit surprising because it has fewer bots it loses against than the last version in all-size suits and [wins more clearly against all minis]. Which is why I upload it. RR@H can say what it wants, I regard this as being the best minibot. =) I would welcome a slight change to the ratings calculations where wins are favoured. That is, I think it should be a bigger rating change gap between 47.5% and 52.5% than it is between for instance 40% and 45% or 55% and 60%. -- PEZ
I agree. Once a bot clearly wins an enemy (lets say 66% of the score) it should not matter if it gets a higher or lower percentage. The same should apply in the other sense (once a bot loses and it is unable to get more that a 33%, it shouldn't be important if it is a 10% or a 30%). It would mean also that for any pair of bots that have a big rating difference, the results would only affect its ratings if they are "unexpected" (that is, a bot that is expected to get 33% or less would affect the enemy rating if he gets more than 33%). Let me know if you like this approacg so I can change the ratings calculations. -- Albert
I though that was why that "S-curve" was used, I agree it seems a bit disadjusted(?). Paul Evans is probably the guy to talk with about changing it... -- ABC
I'm not sure I understand how this scheme would favour wins. Can you elaborate? -- PEZ
If I understand it correctly, it doesn't favour wins, it has an effect similar to what Albert described, the difference of winning by 70% or 90% is much smaller that between 40%-60%. It probably can be "skewed" to favour wins, I am not the guy to do it though, it was Paul who adjusted it to the ER. The problem here is that he did it for a much smaller data set, and for a competition where a bot only fought it's neighbours. -- ABC
In my oppinion, the current rating system (both in RR@H and ER) has two disadvatages:
There proposed approach provides a solution for the problems mentioned:
The global behaviour of the new rating system would be that would disregard results for far rated enemies (unless they get an unexpected result) and would move from a points based rating system to a win/lose rating system, which is globally more intuitive and more robust. -- Albert
I like it. But wouldn't it be better to make the client behave a bit more like the ER and mostly fight bots against their neighbours? It would make the ranking evolve much faster, that's for sure. Wouldn't that have a similar effect as, as you describe it, "ignoring" results of battles between bots with very distant ratings? I sure would like a more "ladder-like" system. -- ABC
Well, one of the things that I like of RR@H is that makes sure a top bot is really a top bot, just because it faces every one. My impression is that bots tend to get overspecialized to kill its neighbourgs, and quite frequently you get nasty surprises when they face bots that should be easily beaten. The proposed system would be a kind of leage, with %scores lower than 30% beeing a lose, higher than 70% beeing a win, and percentages between 30% and 70% beeing a kind of graded tie. Also by limiting the fights to a "local range" the problem about %scores would persist: Is it better a bot that beats all enemies by a 70%, or a bot that loses against an enemy and beats the rest by a 90%? To me, the first one is better, but an ER rating system would probably say the second is best... Of course you can think the other way (to me, what makes DT the best bot is that it beats almost all bots, not its %score) -- Albert
I like it too. And I like the quality of bots having to face all enemies and not just those in the neighbourhood. The speed with which a bot will get a correct rating will increase greatly once the clients try to even out the number of battles each bot fights. Though I don't see 55% as a tie. It's a win. -- PEZ
I think it would be interesting to have both ranking systems side by side using the same data. Some bots are designed to get high scores, some to win, both are valid. Although, i would make it a simple win/lose, and not take any notice of actual %. I guess you would need a draw for actual 50/50 games, but that is very unlikely to ever actually happen. -- Tango
I agree with Tango. Would it be possible to see this side by side to see what the effects of the proposed changes are? I think Albert's proposed %70/%30 scores also make a lot of sense. I think there needs to be some differentiation between bots but at some level it is over kill. Seeing SandboxDT have cf.C8_1.1 listed as a problem bot, after beating it with %70+ of the score is not logical. Would it be possible to simply say that no bot should be expected to win by larger than some margin (ie %70)? What affect would that have on the rankings? -- jim
I guess we can put in place the new rating system and see what happens (and reverse if necessary). We can not have both at the same time (but we all know how the current one works, so it should not be a problem). Please, vote the prefered min/max percentages:
Note that the closer the percentages to 50%, the slower will be the change of the ratings. Also note that a close minimum maximum can not properly deal with uncertain results. -- Albert
Intutively I would have said 45/55, but since Albert says it has significant weaknesses I make a comprimise and vote for 40/60. -- PEZ
45/55 might be a bit too radical. On the other hand, if we want to quickly see the effect of this change, I think we should go for the lower values: 40/60 -- ABC
Hmmm, I don't know if I see the purpose in this. DT can probably beat most top-50 bots about 70%-30%, so I think if cf.C8_1.1 gets 30% of the total score against DT with its general rating, he is a legitimate problem bot for DT. FunkyChicken beats most bots in that rating region with between 70% and 80% of the total score. Statistical targeting sort of assumes you can't generally hit your opponent 100% of the time, and some robots' strength is that they hit some other robots nearly 100% of the time. I see this as a legitimate weakness of such a targeting algorithm, basically that it is less specifically adapted toward bad movement. -- Kawigi
Yeah, it's quite a philosofical question. But using a wild percentage score would be like deciding the winner of the football league based on the number of goals scored by each team, not the number of matches won. Probably it is a legitimate method, but it is quite counterintuitive to me... -- Albert
The football analogy is quite good. Think about a fotball team (we're talking "soccer" here, but I would guess the same goes for american fotball) that wins all its matches during the season and still doesn't top the score board. I and many with me would object. As I object about my test runs showing VertiLeach winning against all minis and still not be the #1 minibot. It's just not intuitive. For the record. I think I would take the same stand if it was Fhqwhgads winning against all other minis. -- PEZ
It does not worry me what rules are used - instead of setting at 70/30 rule just have the system select battles of bots within 200 rating points (or whatever the selected value is) (it won't make much difference). However I am concerned that some of you are writing bots which 'give-up' once they have got 70% of the score - perhaps like football players they are saving themselves for the next match. (what you will find is that by the time you have written a bot that beats DT it will automatically thrash bots further down the rankings). I had a look at the distribution of scores with high difference of rating points with the RR@H scores and the curve looked good to me (others can check - the data is available). For those that wish to count a win as a win and ignore score, why not go the whole hog and count rounds won, or even bullets hit - I'm up for it :). p.s. If you have a bot that is never thrashed but has a low ranking have a look at the gun - good movement against a good gun or a bad gun ensures a near draw, poor movement against a good gun ensures a thrashing. A good mover against DT can get near a draw even if it fires randomly (without firing at all it can get 30% of the score), but movement is only half the story, the present system reflects this truth. -- Paul Evans
I agree with Paul; I think there must certainly be a difference between a 70% win and a 90% win. With the roborumble matching up every bot against every bot, this creates much more room for bot improvement. For example, with data management; bots now have to manage and maintain data on 200 bots rather than just 10 or so. If a system is implemented where anything above 70% is ignored, bots can simply ignore data on bots they already thrash without any more intelligent decision. This is bad. Bots should have to intelligently decide which data to keep and throw away; the way it is now opens the floor to all sorts of impressive data optimization algorithms using rating comparisons to figure out what data is best to keep and throw away. Other examples are for example using APM and anti-gunning curves; against some of the lower bots, the predicted percentages SandboxDT gets of even 90% score against the lower bots should be attainable. Movement algorithms with accurate data can produce bots that can almost never get hit be some of the lower end bots, thus reducing the enemy score to near zero; against lower bots gunning patterns can be written to wait on high-chance shots and fire with almost guaranteed success rates. The floor right now is wide open to make a bot that's totally lethal to the lower end bots; this should certainly matter quite a bit in the score. If we rewrite the ranking system to bound scores by 70%-30%, we lose all sorts of conceptual possibilities that have only begin to develop with the current ranking system of the RR&H. My vote is to leave it the way it is. -- Vuen
Note, that I have only asked for intuitiveness of the rankings. I suggested giving an extra bonus for a win (defined as > 50% score). In all other respects I am quite satisfied with the current system. "Winning against all minis implies battling all minis enough to really be able to tell". I have. I can tell. You can too if you like, just set up a RoboLeague with all minis and run 20 seasons of 35 1v1 battles with VertiLeach as focused opponent. I can also tell that even so my bot doesn't rank #1 among minis. I think that's wrong. I don't see the point in taking it to other extremes, like pure survival or pure hit rates that Paul suggests. Sure we can design a survivalist league with this infrastructure. But that's something else entirely. VertiLeach sure doesn't satisfy with winning 70%. It fights best it can to the end. This shows in its [details]. -- PEZ
One of the advantages of RR@H is that it is becoming the most tested/analyzed/discussed robocode league :-) I don't like the idea of having a rating system and wonder "What if" it was different. Considering we are in testing phase, my proposal is to change to a bounded limits rating system, see what happens (pe. leave it for one week) and discuss again to decide the final rating system. -- Albert
Of course we are in the testing phase. And of course, since it only takes a week, we should test your proposed aproach. -- PEZ
A weeks test sounds like a good plan. I don't see why it couldn't be run side by side though. Couldn't you have 2 versions of RR@H running on the server, and the data for each battle is given to both? -- Tango
I don't think you have to do anything to the league to test a new rating system - I think you have all the necessary information in data files to investigate the effects of different rating systems already. -- Paul Evans
Please do, I can surely try. Maybe you could make the server automatically package it in certain intervals? I made a RR@H server version integrated with a lotus domino server (I'm not very confortable with java servlets), I could maybe even maintain some alternative ratings if the client was changed to submit battle results to multiple servers... can't promise anything about an online server, but at least with a regularly updated all-pairings file I could manually publish some 70/30/wins/survival/whatever ratings. -- ABC
Yeah. I can create an small program that uploads the packaged results to a local server installation (with the modified rating system) and "rebuild" the ratings. --Albert
The all-pairings file has been created weekly for quite a while now. Now I have created fresh files. I've changed it so that it now creates a allpairings_game.zip for each game we are currently running which means roborumble, teamrumble, minirumble, microrumble and nanorumble. I think we may have some broken records left there in the files. I might find those and clean them out later, hope you can work with the files anyway. I have separated the building of wiki published rankings and the allpairings files now so that we can have different schedules. Please let me know how frequently you would like these files built. The roborumble game file is here http:/robocode/rumble/allpairings_roborumble.zip I think you can work out how to reach the other files. =) -- PEZ
Cool, I suspected it was being updated, didn't know it was weekly. I'll do some more experiments with "fresh" data, but leave it to Albert to publish any alternative ratings. -- ABC
On the matter of speed, couldn't the rating constant be set to a higher value in the first 10 battles fought? I was thinking something like this: Every bot starts with 1600 (even new versions). The first few battles (10 is probably good) are run with an increased constant (5x?) and do not influence the enemy's rating. Those battles are "fixed" so that the enemy is allways the closest one on the ranking table. For example: first battle against a "median" bot (1600), the result says it should go up 100 points, 2nd battle against a 1700 bot, it goes down but not so much this time, etc. It would be something like a binary search of a bot's aproximate position before it starts the real test of fighting everybody else... -- ABC
I agree with the idea of not updating the enemy ratings when a new bot fights the first battles, and that increasing the constant during this battles would be good. But I can't agree with the idea of new versions starting at 1600. The best guess for a new version is its previous rating. About the binary search, it presents some concurrency issues (which client would run them? How they syncronize? What happens if the assigned client fails to upload the battles?) that would require too much programing. -- Albert
Oh man... I can't believe I submitted ProtoStar?... -- Vuen
I say it again. When the clients favour battles with new/updated bots, the speed with which the bot find their neighbourhood will be fast enough. -- PEZ
Yes, it would be hard to do with multiple clients, the only way I see it possible is if the author is required to do a qualifying run for a new candidate. Scratch that, just upping the constant should be good.
About that constant (sorry about the brainstorming), I thought it just made things faster by sacrificing some precision, but I got some strange results after some testing. First I did some tests by processing all the pairings with the current formula (rankingdelta = scoredelta * 3), it takes a long time to stabilise, around 20 iterations, and by iteration 14 there are still some bots changing places significantly, namely the ones with less pairings run, like VertiLeach that comes into the top 30 in iteration 14 and climbs to the top 15 by iteration 18. No problem, these are the correct positions if we took these battle results as the absolut truth, I thought. But then I upped the constant by 10x (ranking = score * 30), like I expected it stabilised much faster, 2 iterations for DT to get it's 1860 points and no significant place changes after that. But I got a quite different ranking this way! Chameleon took 2nd place (from 3rd), BlestPain got 6th (from 2nd), and everybody else got shuffled around as much as 5 positions... How do you explain this? Maybe te increased constant favours less specialised bots? Or it just helps bots with fewer results? More/less resistant to flukes? I don't know, but it sure seems it can make the table stabilise much sooner... -- ABC
Just remember that a wiki is a brainstorming tool first and foremost. Storm on. I think that the way to go would be to "quarantine" new/updated bots for some 50 battles or so before they start to impact the ranking of the opponent bots. This combined with clients that try to level the number of battles for the bots in the rumble should do the trick. Interesting that you got different rankings all together with the factor 30. What is a apecialised bot anyway? -- PEZ
I think it is a bot that doesn't follow that S-curve like it should, it wins against some bots it should loose and looses against other it should beat, acording to the current ranking. -- ABC
Like VertiLeach then? (Well, it doesn't loose against many bots, but it has lots of red and green boxes in the ProblemBot index column.) -- PEZ
Yep, unexpected scores (in both directions), not wins/losses. A specialized bot takes longer to find it's spot in the ranking table. -- ABC
You can find a simulated ranking for 70%/30% limits in http://www.geocities.com/albert_pv/Rankings7030.htm -- Albert
About the rankings, I suspect (And the problem is not new to me, but I also felt the same in the ER) that there are many equilibrium points in the rankings (ie. there are many combinations of ratings that make them stable). Some times, the equilibrium is broken and all bots jump to another equilibrium point (an example could be GlowBlow in the Minis competition, just a couple of days ago). In this case, the higher the rating change constant, the easier bots move from one state to another. Also, if the constant is to high, it can happen that ratings never settle into an stable state, and cicle arround. -- Albert
Like Paul said, the 70/30 rule doesn't change much... I'm now convinced that the lack of stability of the ranking is related to the way the ranking is updated and to the constant used in those updates. If you feed the server with the same battles over and over you get a stable ranking at some point, the speed at wich that equilibrium is reached depends on the constant you use, a higher value will make it faster. In my experience, when the top bot (DT) stops going up you have a stable table. What I discovered (and wasn't expecting) is that the position of most of the bots varies a lot depending on the constant used... I'll publish my results later today, I have 20 iterations made with c=3 and 3 with c=30, both seem to have reached a stable equilibrium, but have some major differences in the position of the top30 bots. -- ABC
Doesn't change much? It makes worlds of difference for VertiLeach. I know I'm heavily biased, but the 70/30 boundaries makes the rankings much more intuitive in my opinion. DT only looses to Chameleon. BlestPain only loses to DT, Smoke, Cigaret and VertiLeach. And VertiLeach is the next bot in the row of bots with few bots that can beat it. It's logical with a #3 ranking for Verti. If you don't think it changes much I guess that means you don't mind if we switch to this ranking? My vote is obvious I guess. =) -- PEZ
Hehe, I didn't notice Verti was so high up, Tron also went up from 20th to 14th. Kawigi and Rozu might not be too happy about it though, FloodMini and GlowBlowAPM went down like crazy... It changes a lot, but so do successive iterations of the same formula, so I'm not really convinced that those are stable results. Was that a single iteration through the results, Albert?-- ABC
I simulated how the rankings would be calculated in the server. Picked a random row, feeded it to a local server as a battle, then picked another one, feeded it into the server, and so on. I feeded a total of 168.000 "simulated" battles. BTW, are you feeding the file to your simulation in a linear way? May be the order of the bots is affecting its rating? -- Albert
I agree that rankings change a lot with a 70/30 rule. All Aspids are down with the new system :-( -- Albert
Yes, I'm processing the allpairings file sorted by ascending time of last battle. I do around 19.000 "battles" per iteration, so your method should be roughly equivalent to me doing 8-9 iterations, assuming that the order of the battles doesn't influence the final "equilibrium state". I think I observed a very stable equilibrium at around 400.000 battles (20 iterations), with the normal formula (no 70/30 rule) and c=3. If I have the time I'll try it with the 70/30 formula. I don't think we should change it before we reflect on wich bots go up/down and why... Unless of course PEZ refuses to play if he doesn't see VertiLeach in the 3rd spot. ;) -- ABC
=) I can wait. But for the record, what I find hardest to see is a sub #1 rank among the minibots. Maybe you can run some simulations on that game? -- PEZ
OK, I'w do it tonight. -- Albert
Here are the results of my tests using the normal rule: http://robocode.aclsi.pt/ranking/Ranking_pass1.html
If you replace the 1 in that url with numbers from 1 to 20 you'll see the evolution of each pass through the allpairings file. -- ABC
I tested the minirumble with my simulator: with the current result set (VertiLeach has fewer battles than all the others) and no 70/30 rule, it places 2nd after a lot of passes. With the 70/30 rule it gets to 1st place after a while, with GlowBlowAPM slowly dropping to 6th place and FloodMini holding on to a close 2nd. It seems GlowBlowAPM is a typical bot that suffers from the 70/30 rule, maybe because it is a "generalist" bot? If so, the change to 70/30 has the intended result. I'm not convinced that this is a "good" change, though, even if Tron benefits from it... -- ABC
I have a question. Are a bots results continuely re-evaluated relative to it's current position and all other bots current positions? By that I mean as the new Jekyl 0.55 (hopefully) rises through the ranks, are it's current results re-evaluated to say "That was good enough when you were at #30 but it's no longer a very good result considering where you are now #20"? What about when a result against a bot that was #30 was OK but now that bot has fallen to #50 and they no longer are? -- jim
Nope, the current setup is similar to a rolling average, your results are evaluated after each fight, influence your rating by some factor (the famous constant ;)), and are forgoten. -- ABC
ABC, can you publish those results too please? If you have the time and kindness. Since the file you have contains quite few VertiLeach matches maybe you could test with this file: http:/robocode/uploads/pez/allpairings_test_minirumble.zip It's the results of 400+ RR@H battles with VertiLeach as focused opponent. Verti still has fewer battles than the rest, but 400+ should be enough shouldn't it? -- PEZ
Here you go: http://robocode.aclsi.pt/ranking/miniranking7030.html I'll try it with your test file. -- ABC
About reevaluating results, I have to contradict ABC :-( Results are added to the previous ones (against the same enemy) using a kind of rolling average. This is, a %score is maintained against every enemy. But every time a bot fights a battle, ALL its results (stored as an "average" % of score) are reevaluated against ALL current ratings of the enemies it has fought some time, and a momentum (up or down) is calculated to move the bot up or down. Take a look to the Details page of any bot to see how it works. -- Albert
BTW, I made some simulations and there is a single solution (well... it can be shifted, but the difference between ratings is constant) that satisfies that ALL the momentums are 0. So we are happy now about the robustness of the ratings (changes occur just because convergence speed and variance in the results uploaded). -- Albert
Well, I'm glad I was wrong then. :) I got the wrong impression when I read the server's source code, that should make it much more stable. -- ABC
PEZ, your results using the normal rules: http://robocode.aclsi.pt/ranking/testranking_normal.html
Thanks dude! Nice rankings considering they are with the old school rules. =) -- PEZ
Would anyone object if I set my client to run battles with Jekyl as a focused competitor? I can't see that it should scew the ratings any, it would just speed up the process for the new Jekyl to get its proper ranking. -- PEZ
I certainly would not =^> But I am willing to wait. The suspense is half the fun. -- jim
But painful. Like a BlestPain. =) -- PEZ
PEZ, the same test with "VertiLeach to the throne" rules :), 60/40 this time: http://robocode.aclsi.pt/ranking/ranking_test6040.html, I'm ok with some focused Jekyl fights... -- ABC
Thanks. That's a really nice ranking. I think I will print it on an A2 sheet and put it on the wall. =) -- PEZ
Ha! I think I'll print it on an A2 sheet and BURN IT! ;-) -- Kawigi
I calculated the "solution" for the mini ratings (using the unlimited rating system) and including only the top 20 bots, and VertiLeach gets the first spot. It means that GlowBlow and Flood are 1rst and 2nd just because they perform better against the lower than 20 bots. -- Albert
Maybe it also means that VertiLeach's movement depends on having a good movement to "leech" form? That can be seen as a design flaw. ;) -- ABC
Indeed. Though version 0.2.1 tries to fix that somewhat. Still Verti manages to win against most bots even if their movements sucks. What it finds the hardest is multi-mode bots like Ares and PrairieWolf (and, as a consequence of its design, bots with excellent guns like DT and Tron). VertiLeach aside. Wouldn't you agree that a rating system that selects a bot that beats all other bots as #1 is what we should opt for? -- PEZ
Yes, I agree. But I also agree that the best bot is the one that performs best in all situations. DT beats all bots and is at #1. VertiLeach's case is somewhat special, it seems that it exploits certains weaknesses of the top bots (a bit like I did with DT 1.91 and mirror movement) but does not perform so well as the others at killing the rest of the pack. That also means it has an increased probability (even if a small one) of loosing a battle against an "average" bot. So, in the long run, is it really a better bot than FloodMini? It's a tough question... -- ABC
Of course DT is #1. And as you have seen it's #1 anyway we slice things. Now follow along ... VertiLeach doesn't lose against any minibot. Not to FloodMini, not to any minibot. Exploits some weakness of the top bots? Not of DT, not of Tron. -- PEZ
The RR@H results say that it so far is really close to FloodMini and (at least with version 0.2, since it's seen more battles) it loses to one or two minibots and one or two microbots. Although I don't doubt that under certain conditions, it can beat about anything.
Well, my opinion is still that a bot that can score higher against other bots even if it loses to VertiLeach should occupy the #1 position. Just because VertiLeach wins against all minis shouldn't make it the best; consider two bots, one that beats everybody 55% to 45%, the other that loses to that bot and beats everybody else 80% 20%. I would consider the second bot MUCH more deserving of the top position. I'm not a big fan of this rating cap; just being able to beat everyone denies so many concepts that provide high-scoring points against lower level bots. Verti's current movement is such that even if it can win it has a lot of trouble stomping on bots that others like FloodMini can tear to pieces. As much as I admire VertiLeach's movement, I still feel that FloodMini is the top bot. -- Vuen
That's the first time someone has explained the rationale behind the current ranking system in a way I can almost agree to. But I still think wins should count a little more than it currently does. It would make it more immediately intuitive. -- PEZ
The other problem with just using wins is that over one or two 40-round battles, winning 55%/45% may not be a true victory at all, but a little luck in one way or another. Likewise losing 45%/55%. -- Kawigi
But if instead of 55%/45% is 70%/30% (or whaterver you need to feel comforatble about not beeing just luck). Which bot would be better? I think the first one. -- Albert
To be clear, I think that in Vuen's contrieved example that bot 1 would should be ranked #1. "So, you beat everyone else and so do I, let's decide this in combat just you and I." When it comes to luck or not luck, when you meet 180+ enemies luck and unluck tend to even out and even if not, it will once a bot has been in the league for a couple of weeks. And, as Albert says, noone (but I) has been proposing 55/45. Let's use 70/30 and it should both iron out luck and still leave some room for proving your strength against bots with a low ranking. -- PEZ
...But Robocode has never been the kind of game where a placing is decided on a single match; robots next to eachother in placing don't fight eachother to see who would be ranked first. Scoring in Robocode is not like bowling for example, where your score is completely independant of who you're playing against. Bots will lose to certain bots, but win against others than the bots it loses to can't beat. In other words, it's not the type of game where 'if I can beat you, then I can beat everyone you can beat'. Just because two bots beat everyone else doesn't mean they are equal up to that point, and their ranking should not be decided by the one-on-one matchup of the two. The amount by which they beat everyone else should matter much more then how they do against eachother. In my example up there I still feel that the 2nd bot should by far be ranked #1. -- Vuen
*Pats Vuen on the back* PEZ claims to have tested against quite a large range of minis (and I assume he would have tested against top micros, too, but it appears F-Micro and Smoke give him fits). But its true. When I finished FloodMini 1.3, the reason I predicted he was top 5 material was not because he could beat the #5 at the time (who, come to think of it, may have been Marshmallow). It was because I'd run about 200 or 250 rounds with the entire top 40 and it only lost to 5 of them. And, I suspect, I would find that he wouldn't lose to a lot more among all bots, as I didn't tweak FloodMini to beat anyone in particular. That version was just a general improvement I thought up and implemented. FloodMini is an all-around strong bot, and if you look at specialization indeces, it's one of the most generally dependable bots there are. I don't admire VertiLeach's movement as much, it looks curiously like mine. -- Kawigi
In all my testing Smoke and FhqwhgadsMicro gets beaten by VertiLeach. Not by much, but some 55%+ of the score. Have your testing reached a different result? It sounds like you agree that a bot beating more bots than any other bot is intuitively a #1 candidate? Verti's movement is nothing to be impressed by. It's static distancing if there ever was one. What Verti forces forward is a a battle of the guns and it has a specialized gun for the fighting distance it has choosen. So it is kind of DynamicDistancing too. =) By not allowing FloodMini to choose the distance it gains an edge against FloodMini that few bots can say they have. -- PEZ
Now, I seem to have messed up the wiki published ranking tables badly... Hope I can fix it today. -- PEZ
Well, you're probably right. You guys know way more about this ranking stuff than I do. Whatever you guys agree on is fine by me. -On a lighter note, I'm finally one of SandboxDT's problem bots! :D -- Vuen
This page was getting very long so i have moved some of the older stuff to /OldRankingChat? -- Tango
Good initiative. If someone has the time it would also be good if redundant information on these and other pages got cleaned away. -- PEZ
Question about the rating / rankings. I thought all battles between minis would count in the minirumble. But comparing Griffons details for the minirumble and roorumble games this is clearly not so. Should it? If not, how is it supposed to work? -- PEZ
If you are running the client with RUNONLY = MINIBOTS, the battles will only count for MINI/MICRO/NANO ratings. Also if for some reason a client was unable to check the codesize of the bot, it will upload the battles only to the general ranking. -- Albert
Wow! Griffon is now second and beats SandboxDT (by a very small margin). -- Albert
And VertiLeach seems to have tired of waiting for that rating rules to change. =) #1 in the minibot game! I'm pretty pleased to say the least. Griffon's success shows how extremely important a good movement is. -- PEZ
My question for Paul is how does SandboxDT see the movement of this bot? Paul I know you do not take requests too often for this, but if you are in the mood I would be curious to know what DT thinks. I spent a lot of time on this and would be curious to know if I am on the right track. -- jim
In my 1000 round test DT beat Griffon 55% to 45% (by total score), i think it might be time for paul to release another update. Well done jim and pez! :) -- Tango
![[Home]](/images/RoboWiki.png)